본 글은 사내 업무에서 발생한 이슈에 대해 복기를 하면서 해당 내용이 잘 정리되어 있는 '스프링마이크로서비스 코딩공작소'의 내용을 정리하면서 실습한 내용의 일부입니다.
서론
모든 시스템, 특히 분산 시스템은 장애를 겪습니다. '회복력'을 갖춘다는 것에 있어서 대부분의 소프트웨어 엔지니어는 완전한 장애만을 고려합니다. 다음과 같은 이유로 이렇게 일부분 (완전한 장애)만을 고려하게 되는데요.
- 서비스 degradation(저하)는 간헐적으로 발생하고 확산될 수 있음: 사소한 부분에서 시작된 것이 초기에는 일부사용자의 불평이지만 그것이 완전한 장애로 이어질 수 있습니다.
- 애플리케이션이 대부분 부분적인 저하가 아닌 원격 자원의 완전한 장애를 처리하도록 설계한다: 결과적으로 자원 고갈이 진행되면 호룰하는 클라이언트가 그 자원이 가용해질때 까지 대기해야하는 상황이 발생합니다.
그렇기 때문에 어떤 임계점을 가진 안전장치가 없다면 제대로 동작하지 않는 서비스 하나가 여러 애플리케이션을 다운시킬 수 있습니다.
완전한 장애만을 위한 것이 아닌 장애가 날만한 부분을 미리 탐지를 하고 조치를 취하는 것이 중요합니다. 이것을 포괄하는것이 클라이언트 회복성이라고 표현을 합니다.
클라이언트 회복성에는 네 가지가 있습니다.
- 클라이언트 측 부하분산
- 회로 차단기 (Circuit Breaker)
- 폴백 (Fallback)
- 벌크헤드(Bulkhead)
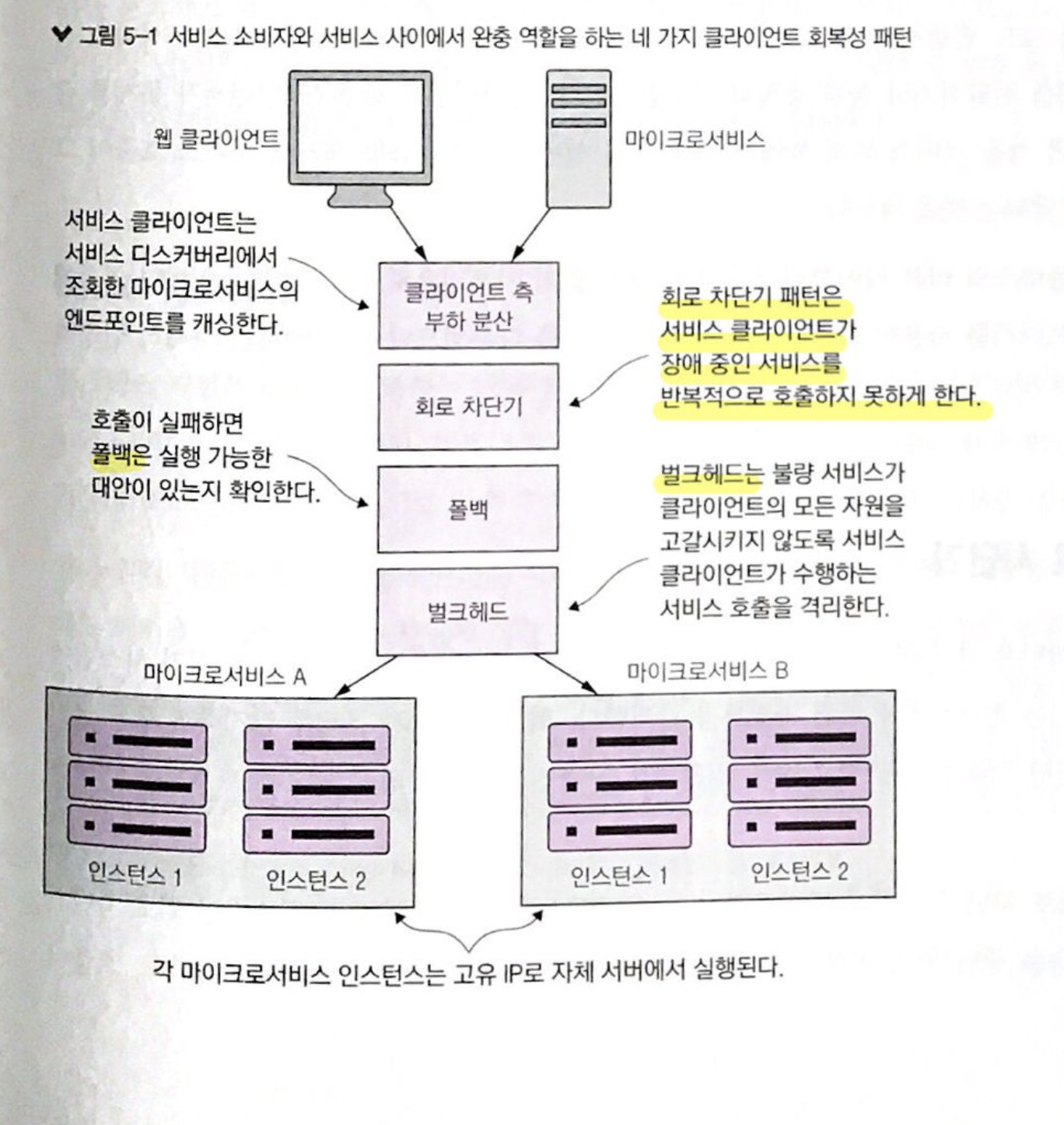
이제 이 회복성패턴에 대해서 알아보려고 합니다. 첫 번째 클라이언 측 부하분산은 이번 포스팅 주제인 회로 차단전략을 설명함에 있어서 (밀접한 관련은 있지만) 부가적인 것이므로 다음에 소개하는 것으로 하겠습니다.
회로 차단기 (Circuit Breaker)
회로 차단기 패턴은 전기 회로의 차단기를 본떠 만든 회복성 패턴입니다. 이름 그대로 전기선에 유입된 과전류를 감지하는데 이와 마찬가지로 하위 컴포넌트가 과전류에 손상되지 않도록 보호합니다.
회로 차단기는 원격 자원에 대한 모든 호출을 모니터링하고 임계점까지 실패한다면 회로 차단기가 활성화 되어 빠른 실패를 유도합니다. 그리고 문제가 있는 원격 자원을 더 이상 호출하지 못하게 합니다.
폴백 (Fallback)
폴백을 사용하면 원격 서비스에 대한 호출이 실패할 때 예외를 발생시키지 않고 대체 코드를 실행해 다른 방법으로 작업을 수행할 수 있습니다.
벌크헤드 (Bulkhead)
벌크헤드는 선박을 건조하는 개념에서 유래했습니다. 선체에 구멍이 뚫리면 격벽으로 구분되어 있는 구역을 제한하여 배 전체의 침수를 방지할 수 있습니다. 이 패턴을 적용하게 된다면 원격 자원에 대한 호출을 자원 별 스레드 풀로 분리를 합니다. 그렇기 때문에 특정 원격 자원 호출이 느려지더라도 다른 자원들에 대한 호출은 영향이 없습니다.
회복성 전략 예시
책에서 소개하는 좋은 예시를 보겠습니다.

각 서비스를 빨간색 네모로 표시를 해보았고 장애 포인트를 초록색 선으로 그어놓았습니다.
애플리케이션 A와 B는 서비스 A를 사용합니다. 서비스 A는 디비 A를 사용하고 서비스 B를 사용합니다. 서비스 B는 디비 B를 사용하고 서비스 C를 호출합니다. 서비스 C는 NAS에 데이터를 읽고 씁니다.
그런데 어떤 관리자가 NAS 작업을 변경을 했네요. 그랬더니 읽기 속도가 저하가 되었습니다. 이제 전파가 어떻게 되는지 보겠습니다.
서비스 B쪽의 개발자들은 그 사실을 몰랐죠. 외부 C에서의 호출과 본인들 디비B에 저장하는 작업을 한 트랜잭션으로 묶은 상태로 만든 작업이 계속 실행이 되고 있는 상태입니다.
서비스 C를 호출하는데 지연이 되면서 요청이 스레드 풀에 쌓입니다. 그리고 커넥션을 계속 물고 있기 때문에 데이터베이스 커넥션도 고갈되기 시작합니다. 점점 느려지는 상황에서 애플리케이션 A와 B도 느려진 서비스 B를 사용하면서 덩달아 느려지기 시작합니다.
결국 모두 다 느려지면서 장애 전파가 됩니다.
여기서 필요한게 회로 차단기 입니다. 서비스 C 호출하는 부분에 (초록색 선 끝부분) 회로 차단기를 두었다면 서비스 C가 제대로 수행되지 않을 때 차단기가 내려가 스레드를 더 점유하지 못하도록 막습니다. 그렇기 때문에 회로 차단기는 애플리케이션과 원격 서비스 사이의 중개자 역할을 하게 됩니다.
회로 차단기가 어떤식으로 동작하는 걸까요?
위에 언급한 회로 차단기를 사용하는 방법은 서비스 C를 직접호출하는 것이 아닌 회로 차단기에 요청을 위임합니다. 회로 차단기는 위임해준 호출을 스레드로 감쌉니다. 회로 차단기는 그 스레드를 모니터링하고 있고 스레드가 너무 오래걸린다 하면 호출을 중단합니다. 서비스 C로의 호출이 회로 차단기로 인해 차단이 된다면 회로 차단기는 발생한 실패 횟수를 추적까지 합니다.
이 과정을 정리해보겠습니다.
- 서비스 B는 회로 차단기를 달았으므로 실제 차단기가 내려가기 전까지 (타임아웃) 문제가 있다는것을 즉시 알게 됩니다.
- 빠른 실패를 하거나 폴백 중 선택을 합니다.
- 차단기가 내려간다면 서비스 C로의 요청이 없기 때문에 (복구됐나 찔러보는 자동 확인 작업은 논외) 서비스 C는 복구할 시간을 갖습니다. → 연쇄 장애 방지
2번 과정의 빠른 실패는 시스템 전체를 다운 시키는 자원 고갈을 막습니다. 또한 차단기가 내려가기전에 다른 로직을 태울 수 있습니다. 예를 들어 외부 서비스에서 데이터를 보여주어야 하는데 그것이 느려져 차단기가 내려가기전에 본인들 디비에 저장된 임시 정보를 보여주는 작업(폴백)을 할 수 있겠죠.
Hystrix 히스트릭스의 사용
스프링 클라우드와 넷플릭스 히스트릭스에서 제공하는 라이브러리를 사용하여 이 작업들을 구현할 수 있습니다.
spring-cloud-starter-netflix-hystrix이 관련 의존성들을 추가합니다.
그리고 사용하려는 Boot 애플리케이션에 @EnableCircuitBreaker를 명시해줍니다.

그리고 메서드에 회로차단기를 다려면 @HystrixCommand 애노테이션을 사용합니다. 스프링이 이 애너테이션을 만나면 이 메서드를 감싸는 프록시를 만듭니다. 그리고 확보한 스레드가 있는 스레드 풀로 해당 메서드에 대한 모든 호출을 관리하게 됩니다.
@HystrixCommand
private Organization getOrganization(String organizationId) {
return organizationRestClient.getOrganization(organizationId);
}회로 차단기 타임아웃 사용자 정의
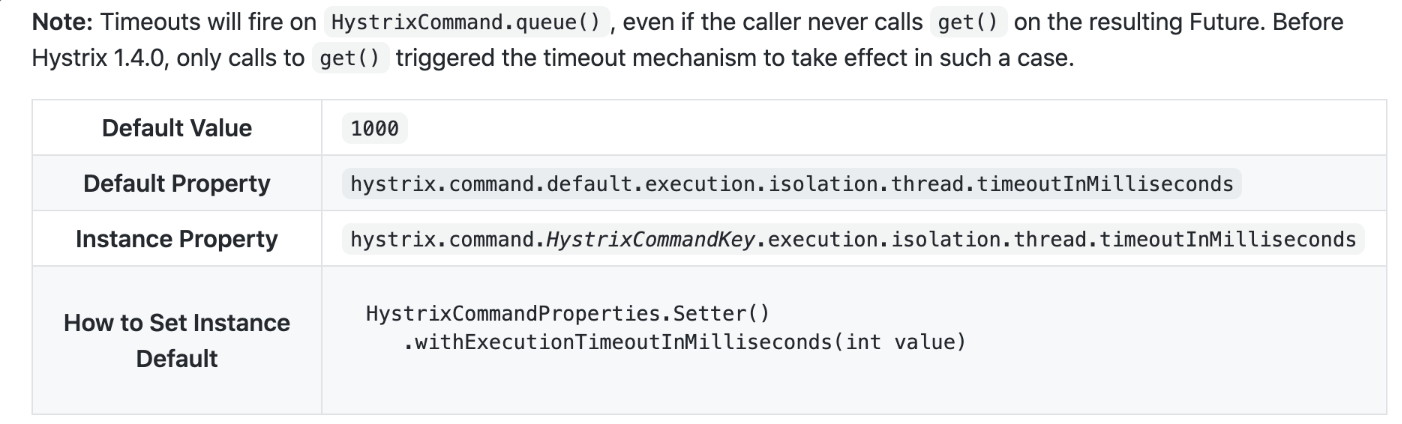
다음과 같이 timeoutInMilliseconds 속성을 사용하여 히스트릭스 호출이 실패하기 전까지 대기할 최대 타임아웃 시간을 설정할 수 있습니다. 전체 속성은 이따가 다시 살펴보겠습니다.

디폴트 타임아웃을 찾아보니 1초네요. 1초 이상 걸린다면 호출을 중단할 겁니다.
주의점은 느리게 실행되는 서비스 호출을 최대한 해결을 해야한다는 것입니다. (빨라지게끔..) 그 서비스가 느리다고해서 히스트릭스 타임아웃을 그 수치에 맞추는 것은 의미가 없습니다. 여러 api중 일부가 느려진다면 그 서비스 호출을 별도 스레드로 분리하는 것을 고려해야 합니다.
이 애노테이션은 큰 장점이 있는데요. 디비 엑세스나 타 api를 호출하는데 있어서 동일한 애노테이션으로 처리가능하다는 점입니다.
예를 들어 RestTemplate을 사용하면 그 restTemplate 호출만을 메서드로 분리하고 @HystrixCommand를 붙여주면 됩니다.
주의할 점은 실제로 사용할 때는 기본설정을 사용하면 안되고 본인에 맞게 커스텀을 해야 한다는 점입니다.
폴백
히스트릭스에서 호출이 실패할 경우 fallback 메서드를 실행되게 할 수 있습니다. 실제 api와 반환형이 동일한 메서드를 정의해야하는 것은 당연하겠죠.

주의점은 폴백 메서드 내부에서 하는 행동이 2차적으로 장애를 발생시킬 수 있을 수 있다는 점을 고려해야 한다는 점입니다. 즉 폴백 메서드 내부에서 하는 행동도 장애가 날 수 있음을 인지하며 방어적으로 만들어야 합니다.
벌크헤드
벌크헤드 패턴을 사용하지 않는다면 기본적으로 전체 자바 컨테이너에 대한 요청을 처리하는 스레드에서 이루어집니다.
벌크 헤드 패턴은 자신의 스레드 풀에 격리시키므로 전체적인 장애를 방지합니다.

threadPoolKey에 스레드 풀의 고유이름을 정의합니다. 그리고 coreSize 속성은 스레드 풀의 스레드 개수를 정의하고 maxQueueSieze로 스레드 풀 앞에 배치할 큐와 큐에 넣을 요청수를 정의합니다. 스레드들이 분주할 때 스레드 풀 앞단에 요청을 백업할 큐를 만드는 것입니다. 요청 수가 큐 크기조차 초과하게 된다면 추가 요청들은 전부 실패합니다.
maxQueueSize에 대한 공식문서를 찾아봤는데요. 기본적으로 -1 이 디폴트 값입니다. 그리고 디폴트 값인 -1을 사용하게 되면 SynchronousQueue를 사용하고 그렇지 않다면 양수를 쓰면 LinkedBlockingQueue를 사용한다고 나와있습니다. (자세한 내용은 해당 키워드로 찾아보세요)

LinkedBlockingQueue를 사용하면 모든 스레드가 분주하더라도 더 많은 요청을 큐에 넣을 수 있습니다. 그리고 이것이 적용되려면 앱을 다시 시작해야 합니다.
주요 속성
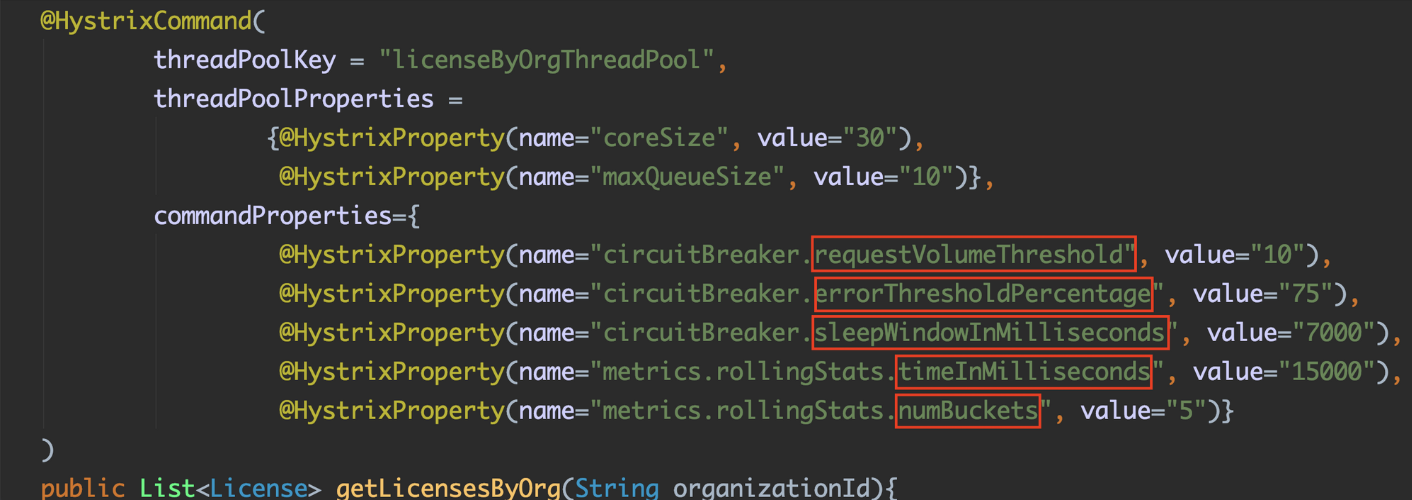
- requestVolumeThreshold
히스트릭스가 회로를 차단할지 검토하는데 필요한 최소 요청 수를 나타냅니다. 디폴트 20회
예를 들어 값이 20 이라면 반복시간 (예를 들어 10초라면) (가정) (공식문서에서는 rolling window 라는 단어로 표한하네요) 내에 19번 모두 실패하더라도 회로가 차단되지 않습니다. 판단하는데 최소 20번이 필요하기 때문이죠.
- errorThresholdPercentage
반복시간 내에 회로를 차단할지 결정하는 실패 비율입니다. 디폴트 50%
- sleepWindowInMilliseconds
회로가 차단된 이후 히스트릭스가 다시 호출 해보는 대기 시간입니다. 디폴트 5초
- metrics.rollingStats.timeInMilliseconds
히스트릭스가 모니터링할 시간 간격입니다. requestVolumneThread가 사용하는 rolling window 값입니다. 디폴트 10초
- numBuckets
히스트릭스가 모니터링 시간 간격에서 유지할 측정 지표의 버킷 수입니다.
문제 상황

실제로 겪은 문제는 다음과 같습니다. 메인화면 진입시 10개 이상의 많은 api들을 호출을 하는데요. 그중 외부 협력사의 api가 아주 오래걸리는 상황이 발생했습니다. (그 때의 기억을 대략적으로 살려서.. 단위는 ms) 비동기로 데이터들을 조합을 하지만 결국에는 제일 오래 걸리는 api에 맞춰서 데이터가 완성이 될텐데요. api응답이 5000, 7000ms로 떨어진다는것은 매우 심각한 상태입니다.
하지만 서킷이 열리기 전까지의 조건이 충족되지 않아 그냥 계속 느린상태로 응답이 오고있었습니다. 인스턴스가 여러대 떠있었기 때문에 로드밸런싱된 요청이 각 인스턴스에 뿌려질건데 그 뿌려진 요청량이 서킷의 requestVolumeThreshold를 충족을 못시킨 겁니다. 요청이 더 많이 들어왔으면 threshold에 걸려서 서킷이 열리고 응답속도가 빨라졌을텐데요. 딱 그 시간대에 매우 애매한 요청량 때문에 서킷이 열리지 않은 상태로 모두가 느린 페이지를 받게 되었습니다. 결국엔 이 상태를 임시로 해결하기 위해서 팀원분들이 협력사에 연락을 해 그쪽 내부 상황을 파악하는 한편 requestVolumeThreshold를 낮추고 (서킷 판단 조건을 더 타이트하게) errorThresholdPercentage 도 일부 낮춰서 일단 서킷이 열리게끔 hotfix를 하였습니다.
사용하는 애플리케이션쪽에서도 서킷으로 장애전파를 막고 그 시간동안 외부 api를 담당하는 협력사가 해결할 시간을 준 것이죠. 어찌됐건 메인 진입시 저런 상황이 발생했기 때문에 정책적으로 서킷설정들을 더 타이트하게 가져가게끔 변경하는것으로 마무리되었습니다.
참조
스프링 마이크로서비스 코딩 공작소 - 길벗
'프로그래밍 > Spring' 카테고리의 다른 글
| Spring Cloud Config를 활용하여 설정값(properties), 비밀번호 숨겨서 배포하기 (1) | 2019.12.09 |
|---|---|
| Pivotal Summit 2019 Seoul 참가기 (0) | 2019.11.21 |
| REST API 에러 핸들링 best practice - 에러를 어떻게 내려 주어야 할까 (1) | 2019.11.20 |
| [Spring] @Transactional 롤백은 언제 되는 걸까? - 예외가 발생했는데도 DB 반영이 된다고? (4) | 2019.11.10 |
| [Spring] Jenkins(젠킨스)를 활용한 스프링부트 앱 간단 배포하기 (11) | 2019.08.24 |