화요일에 Pivotal Summit 2019 Seoul에 다녀왔다.
https://connect.pivotal.io/summit_2019_seoul
Pivotal Summit 2019
Pivotal Summit 2019 is coming to APJ! Join us for valuable facetime with expert Pivotal speakers and industry thought leaders in both traditional presentation and informal conversations. We'll discuss the latest developments in DevOps, CI/CD, application d
connect.pivotal.io

왼쪽부터 폴 자코스키, 나, 마크 헤클러, 스펜서. 1년에 한 번 Java Champion들과 어깨를 나란히 해 볼 수 있는 기회..!
작년엔 조쉬 롱이 왔었는데 이번에는 집안 일이 생겨 투어 중도에 미국으로 갔다고 한다. (작년에 싸인을 못 받은게 너무 아쉬웠지만) 결국 조쉬 롱의 세션을 마크가 대신 진행했다.
세션은 총 7개로 진행되었다.
Spring Into Kubernetes
Diving into Reactive
To Strangle or Not To Strangle: Tackling the Monolith
고객 사례: 국내 금융권 고객사의 Cloud기반 Pivotal PAS 도입 사례
Drinking from the Stream: How to Use Messaging Platforms for Scalability & Performance
Bringing Cloud Databases On-Premises with Greenplum and Kubernetes
Living on the Edge With Spring Cloud Gateway
오후 세션이라 자리가 좋은 자리가 다 찼을 거라고 생각했는데 운 좋게 앞자리가 몇 개 비어있어서 좋은 자리에 앉을 수 있었다. 우연히 영한님과 용근님도 만나서 인사를 드렸다.
한 번 듣고 이해하기 어려워서 몇 개의 세션만 복기해보려고 한다. (Diving Into Reactive, Drinking from the Stream, Living on the Edge with Spring Cloud Gateway)
Spring Into Kubernetes
연사: 폴 자코스키

키워드만 정리해보았다... 추후 공부해야할 주제들로 정리해야될것같다.
컨테이너는 도커 이전에도 존재했었다. 도커는 표준화된 컨테이너로 만들어졌다.
컨테이너는 자원을 고립시키고 추상화시킨다.
image를 빌드 할 때 는 최대한 리소스를 압축시켜야 한다.
쿠버네티스는 Control Plane, Data Plane으로 나눠져있다.
Controller: 는 Desired State, Actual State 로 loop을 돈다. 언제나 원하는 작업을 보장하는 과정
kubectl 로 run scale create를 할 수 있다. apply로 yml 파일자체를 실행할 수 있다.
Pods, Services, Volumes 가 애플리케이션을 돌리는데 있어서 가장 중용한 3가지이다.
Pods: 한 개 이상의 컨테이너가 네트워크와 저장소를 공유한다. Nginx로 뜨는 컨테이너와 Apache로 뜨는 컨테이너끼리 통신할 수 있다.
kubectl deployment는 애플리케이션의 생명주기를 관리한다. replicas로 복제할 수 있다. node fail에 대해 보장할 수 있다. 하나가 날아가면 바로 지정했던 숫자의 노드로 복구를 한다.
cluster ip, external ip
Volumes: 모든 컨테이너가 사용할 수 있는 디렉토리. 주로 Pod의 라이프 사이클을 공유한다.
[Spring Cloud Kubernetes]
애플리케이션이 잘 동작하는지 확인할 수 있다.
Service Discovery
Native Service Discovery: Config 서버가 필요없게 해준다.
Prometheous: 의존성 추가만해주면 자동으로 해준다.
Diving into Reactive
연사: 마크 헤클러
Reactive Programming
키워드 : 논블로킹, 적은 수의 스레드로 동작하는 이벤트 방식 애플리케이션, 역압
스레드가 제한이 있으면 사용자가 많이 들어온다면 한계가 있다. Reactive는 적은 수의 스레드로 이벤트 룹을 돌려 대기하는 시간을 줄인다. 응답이 완료가 되면 알림을 받는다.
비동기 프로그래밍은 쉽지 않고 클린하지 않는다. 기존에는 콜백헬이 있었다. 다른 문제는 가독성 뿐만 아니라 Producer가 values를 너무 많이 내게되면 Cosumer가 처리하지 못하는 문제가 있다. 이 문제는 Consumer가 이만큼은 처리 못해 나는 요만큼만 처리할 수 있어라고 말해야 한다. Slower Consumer가 이 문제를 처리한다. (이것에 대해서는 좀 더 찾아봐야할듯하다)
Reactive Stream 에는 4가지 인터페이스가 존재한다.
Publisher<T>, Subscriber<T>, Subscrpitoin, Processor<T,R>구현해서 쓰던가 이 인터페이스를 구현하는 Project Reactor를 쓴다.
키워드: Full duplex, Both bidirectional communication.
RSocket
Rsocket을 공식 지원하는 것으로 바뀌었다고 하는데 이것에 대해서 조금 찾아보았다.
RSocket은 이진 프로토콜로 TCP, WebSocket과 같은 바이트 스트림 전송을 위해 사용된다.
RSocket이 왜 나왔나
크고 분산된 시스템은 여러 팀들에 의해 모듈화 되고 다양한 기술과 언어를 사용하게 된다. 이러한 분산된 조각들은 안정적으로 통신해야 하고 빠르게 지원할 수 있어야 하고 독립적으로 진화할 수 있어야 한다. 모듈 간 효과적이고 확장 가능한 통신은 분산시스템에 있어서 중요한 관심사 이다. 사용자 경험에서 레이턴시가 얼마나 나오고 시스템을 운영하는데 있어 얼마의 자원을 쓰느냐에 영향을 미친다.
"RSocket"프로토콜은 "reactive"한 것들을 포괄하는 포멀한 통신방법 이다.
Message Driven
네트워크 통신은 비동기 이다. RSocket 프로토콜은 이것을 포괄하고 단일 네트워크 커넥션 사이에서 다중화된 메세지 스트림으로 모델링하고 응답을 기다리는 동안 블락킹하지 않는다.
모델 종류
Fire-and-Forget
Future<Void> completionSignalOfSend = socketClient.fireAndForget(message);요청/응답 모델에서 응답이 별로 중요하지 않을 때 최적화 할 수 있는 방법이다. 중요하지 않은 이벤트 로깅 같은 경우 이 모델이 유용하다.
Request/Response (single-response)
Future<Payload> response = socketClient.requestResponse(requestPayload);기본적인 요청/응답 모델이 계속 지원된다. 하지만 요청을 블락하지 않는다.
Request/Stream (multi-response, finite)
Publisher<Payload> response = socketClient.requestStream(requestPayload);콜렉션이나 리스트 응답으로 생각하면 된다. 통째로 하나의 응답으로 오는 것이 아니라 스트림으로 온다
- 영상의 목록을 가져오기
- 카탈로그의 상품들을 가져오기
- 파일을 줄 단위로 가져오기
Channel
Publisher<Payload> output = socketClient.requestChannel(Publisher<Payload> input);채널은 양방향 통신이다. 양방향 통신이 없다면 효율적으로 변경부분만 업데이트되는 것이 아니라 클라이언트는 초기 요청을 취소하고 재 요청을 보내고 데이터를 다시 받아야 한다
- 클라이언트가 구독을 계속해서 업데이트 하는 경우
자세한 내용은
http://rsocket.io/docs/Motivations 를 참고 바랍니다.
스프링은 이 RSocket을 공식 지원한다는데 어떻게 하고 있는지 열어보았다.

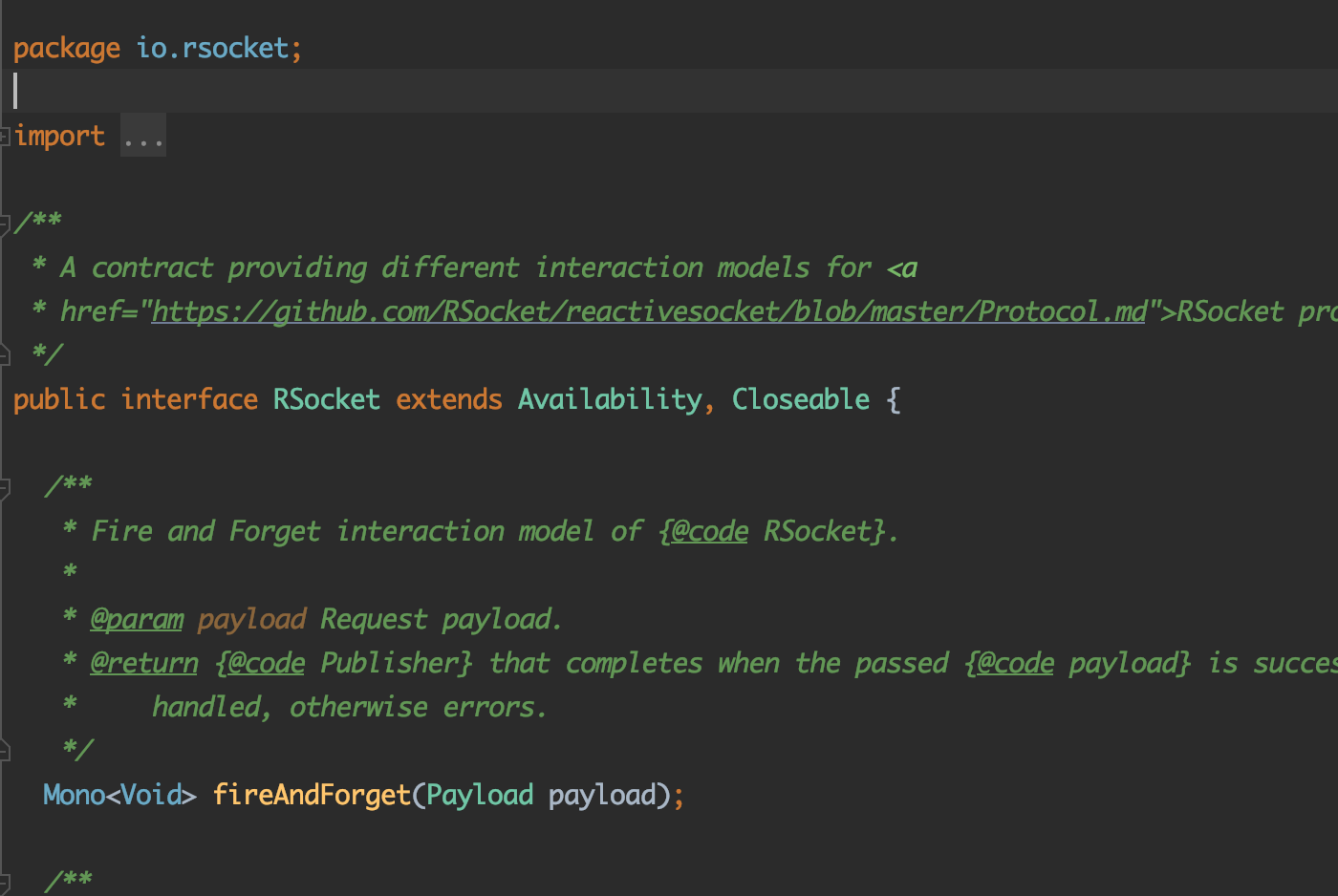
위에서 소개한 4가지 방법에 대한 인터페이스이다. 이것을 구현하는 AbstractRSocket의 모습은 다음과 같다.

주석의 설명에 따르면 모든 메서드는 에러를 던진다고 한다. (마치 서블릿에서 등장하는 추상클래스의 doGet(), doPost()안에서 구현하지 않고 직접 쓰면 Exception을 던지는 것 처럼) 그래서 반드시 오버라이드해서 유효한 구현체를 만들어서 써야 한다고 나와 있다. AbstractRSocket이라는 기본 틀만 제공해주는 것이다. 아마 여기까지 주는 듯 하고 이제 Spring의 서비스 추상화가 나와야 될 것 같은 기분이다.

예상대로 Spring의 spring-messaging 패키지 쪽에서 AbstractRSocket을 가지고 구현체를 만들었다. 5.2부터 새로 만들어졌다고 나와 있다.
여기까지 확인해보고 세션내용을 실습해보았다.
마크가 커피를 좋아해서 커피-커피 주문에 대한 도메인으로 실습을 했다. coffee-server, coffee-client 두 개의 모듈로 진행을 했다.
전체 코드는 여기를 참고하세요
https://github.com/JunHoPark93/pivotal-summit-2019
JunHoPark93/pivotal-summit-2019
Contribute to JunHoPark93/pivotal-summit-2019 development by creating an account on GitHub.
github.com
목적: 기존 방식으로 stream 데이터 받아보기, RSocket을 이용해서 받아보기
coffee-server
서버 의존성: Spring Reactive Web, RSocket, Reactive MongoDB, embedded Mongo DB, Lombok
참고로 embedded Mongo DB는 테스트를 위해서 추가된 의존성인데 현재 실습은 몽고 db를 띄우지 않기 때문에 maven이나 gradle에서 test scope를 제거해주어야 한다.
@Component
@AllArgsConstructor
public class DataLoader {
private final CoffeeRepository coffeeRepository;
@PostConstruct
void loadData() {
coffeeRepository.deleteAll().thenMany(
Flux.just("Café Cereza", "Don Pablo", "Espresso Roast", "Juan Valdez", "Kaldi's Coffee", "Kona")
.map(Coffee::new)
.flatMap(coffeeRepository::save))
.thenMany(coffeeRepository.findAll())
.subscribe(System.out::println);
}
}앱이 뜰 때 저 커피 객체들을 로드한다.
@RestController
@RequestMapping("/coffees")
@AllArgsConstructor
public class CoffeeController {
private final CoffeeService coffeeService;
@GetMapping
Flux<Coffee> all() {
return coffeeService.getAllCoffees();
}
@GetMapping("/{id}")
Mono<Coffee> byId(@PathVariable String id) {
return coffeeService.getCoffeeById(id);
}
@GetMapping(value = "/{id}/orders", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
Flux<CoffeeOrder> orders(@PathVariable String id) {
return coffeeService.getOrdersForCoffee(id);
}
}(Mono, Flux에 대한 설명은 너무 길어서 여기서 정리하지 않으려고 한다. 내용도 방대하고 조금씩 공부해 나가야할 것 같아서 나중에 따로 정리해보려고 한다)
그리고 세 번째 메서드를 보게 된다면 produces 에 TEXT_EVENT_STREAM_VALUE가 있는데 저 url로 오게되면 stream 데이터를 받는 것이다. 저 api는 1초마다 커피 주문 데이터를 계속 받을 것이다.
@Service
@AllArgsConstructor
public class CoffeeService {
private final CoffeeRepository coffeeRepository;
public Flux<Coffee> getAllCoffees() {
return coffeeRepository.findAll();
}
public Mono<Coffee> getCoffeeById(String id) {
return coffeeRepository.findById(id);
}
public Mono<Coffee> getCoffeeByName(String name) {
return coffeeRepository.findCoffeeByName(name);
}
public Flux<CoffeeOrder> getOrdersForCoffee(String coffeeId) {
return Flux.interval(Duration.ofSeconds(1))
.onBackpressureDrop()
.map(coffee -> new CoffeeOrder(coffeeId, Instant.now()));
}
}그 스트림 데이터를 주기위해 다음과 같은 서비스를 만들었다. 마지막 메서드를 보면 Flux (계속 데이터를 내려주어야 하므로) 의 interval로 1초 마다 커피 주문 데이터를 주는 것이다.
onBackpressureDrop은 문서를 찾아보았는데,

제한 없는 요청이 계속 들어올 때 어떤 필터 역할을 하는 것으로 이해했다. 필요 이상의 데이터가 내려오는 것을 막아주는 것 같다. 이 부분도 추가학습이 필요해보인다.
결과적으로 1초마다 해당 커피의 주문 데이터를 계속 받을 것이다.
coffee-client
의존성: db 의존성 빼고 서버와 같다.
8080에 서버가 있으므로 client는 8081에 띄워준다.
@Component
@AllArgsConstructor
public class CoffeeClient {
private final WebClient webClient;
@PostConstruct
public void runIt() {
webClient.get()
.uri("/coffees")
.retrieve()
.bodyToFlux(Coffee.class)
.filter(coffee -> coffee.getName().equalsIgnoreCase("kona"))
.flatMap(coffee ->
webClient.get()
.uri("/coffees/{id}/orders", coffee.getId())
.retrieve()
.bodyToFlux(CoffeeOrder.class))
.subscribe(System.out::println);
}
}
@Bean
public WebClient client() {
return WebClient.create("http://localhost:8080");
}/coffees 로 요청을 보내서 retrive()를 하게되면 body를 어떤 형태로 받을지 결정할 수 있다. Coffee들을 받을 것이므로 Flux로 받고 거기서 kona라는 커피를 filtering 한다. 그리고 아까 정의한 1초마다 주문 데이터를 받아오는 api를 호출한다.
1초마다 해당 주문이 계속 나오는 것을 볼 수 있다.
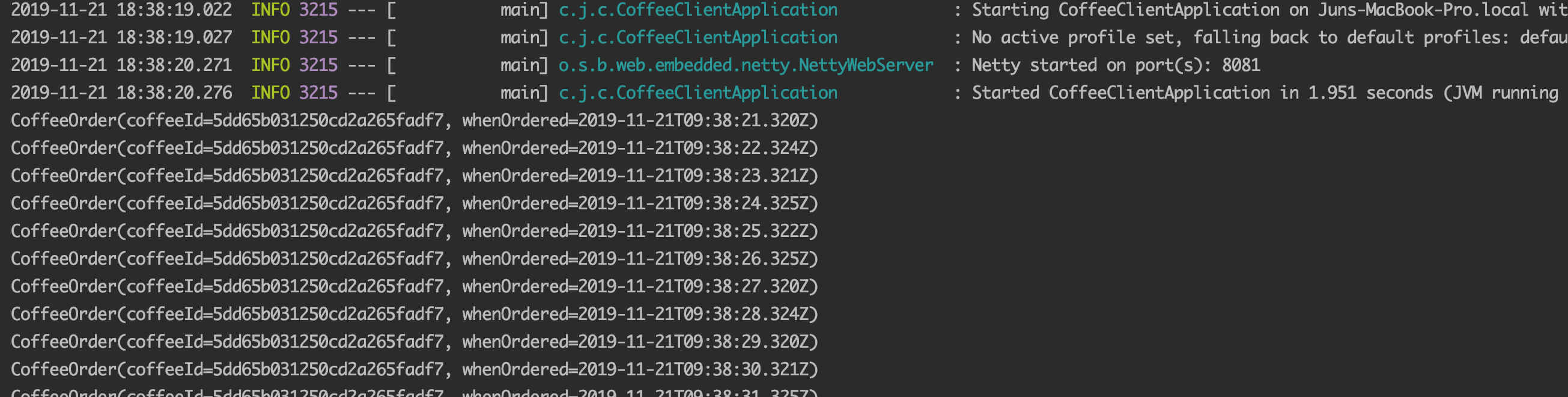
이것을 RSocket을 이용한 방법으로 변경했다.
저장소의 step2 브랜치에 해당 내용이 있다.
https://github.com/JunHoPark93/pivotal-summit-2019/tree/step2-rsocket
server
spring.rsocket.server.port=8901rsocket을 8901 포트에 띄워준다.
@Controller
@AllArgsConstructor
public class RSCoffeeController {
private final CoffeeService coffeeService;
@MessageMapping("/coffees")
public Flux<Coffee> all() {
return coffeeService.getAllCoffees();
}
@MessageMapping("orders.{coffeeName}")
public Flux<CoffeeOrder> orders(@DestinationVariable String coffeeName) {
return coffeeService.getCoffeeByName(coffeeName)
.flatMapMany(coffee -> coffeeService.getOrdersForCoffee(coffee.getId()));
}
}
client
@Bean
public RSocketRequester requester(RSocketRequester.Builder builder) {
return builder.connectTcp("localhost", 8901).block();
}
@RestController
@AllArgsConstructor
public class ClientController {
private final RSocketRequester requester;
@GetMapping("/coffees")
public Flux<Coffee> all() {
return requester.route("/coffees").retrieveFlux(Coffee.class);
}
@GetMapping(value = "/orders/{coffeeName}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<CoffeeOrder> orders(@PathVariable String coffeeName) {
return requester.route("orders.".concat(coffeeName)).retrieveFlux(CoffeeOrder.class);
}
}클라이언트에서 RSocket으로 데이터를 받아오려면 RSocketRequester가 필요하다. 코드를 보면 무슨 기능인지 이해가 될 것이다.

먼저 번의 예시처럼 RSocket을 이용해서 다음과 같이 구현해볼 수 있음을 알 수 있다. (자세한 내용은 깃 허브 코드를 참조해보세요)
비지니스 관련 세션
다음 두 세션은 팀의 운영과 비지니스 관련 세션이었다.
Drinking from the Stream: How to Use Messaging Platforms for Scalability & Performance
TODO 실습 정리중...
Bringing Cloud Databases On-Premises with Greenplum and Kubernetes
연사: 박춘삼 전무, Pivotal
AI is eating software
Pivotal Greenplum - 오픈소스임에도 불구하고 통합적인 ai 플랫폼
개발자가 ai를 이용하는 법 - 일반 개발잔데 내가 ai를 할 수 있을까에 대한 고찰
플랫폼을 kunbernetes를 통해 올린다. (설치과정이 매우 간소화)
데이터 로드 (Greenplum을 통해서 로드)
복잡한 질의 실행 (하나의 쿼리로?)

POSTGIS 가 탑재 지리에 관한 질의도 편하게 할 수 있음 (3천라인의 하둡작업을 32줄로)
ai는 잘은 모르지만, 운영하기 싫고 일반 개발잔데 ai 하고 싶은 개발자들이 편하게 ai 를 이용해서 개발할 수 있는 제품에 대한 소개였다.
Living on the Edge With Spring Cloud Gateway
TODO 실습 정리중...
정리
새로운 것들이 마구 쏟아져나오고 공부할게 참 많은 것 같다. 이런 세미나들을 다니면서 키워드들을 많이 얻어가고 할 수 있는 한 실습을 최대한 해보려고 한다.
마지막으로 작년에 내가 너희처럼 멋진 개발자가 되고 싶다고 했더니, 인사이트를 강하게 주었던 마크형의 한마디...

우리들도 학생들일뿐이고 다 같이 배우는거다. 우리가 서로 더 공유할 수록 우리는 더 성장할 거다.
Java Champion인 그도 자신을 학생이라고 말한다. 그리고 수준높은 공유문화를 실천한다. 같이 공부하고 공유하고 성장한다라는 말이 가슴에 와닿았다. 나도 저들처럼 겸손하고 노력하는 사람이 되어야겠다.
올해도 어김없이 멋지게 떠난 마크형...
내년에는 나도 더 성장해서 다시 볼 수 있기를...
'프로그래밍 > Spring' 카테고리의 다른 글
| Netflix Hystrix를 사용한 클라이언트 회복성 전략 개념정리 (5) | 2020.07.11 |
|---|---|
| Spring Cloud Config를 활용하여 설정값(properties), 비밀번호 숨겨서 배포하기 (1) | 2019.12.09 |
| REST API 에러 핸들링 best practice - 에러를 어떻게 내려 주어야 할까 (1) | 2019.11.20 |
| [Spring] @Transactional 롤백은 언제 되는 걸까? - 예외가 발생했는데도 DB 반영이 된다고? (4) | 2019.11.10 |
| [Spring] Jenkins(젠킨스)를 활용한 스프링부트 앱 간단 배포하기 (11) | 2019.08.24 |