본 글은 RealMySQL 도서를 스터디하며 읽은 내용 + 실습한 내용입니다.
Between을 써서 쿼리를 작성하는데 있어서 비효율적으로 탈 수 있는 쿼리를 개선해 볼 수 있는 내용을 다루었습니다.
테스트 데이터 세팅
실습을 하려면 실제 쿼리를 수행해보고 실행계획을 확인할 수 있는 환경이 필요하다.
먼저 테이블은 컬럼을 간단히 만들었다. (id, position, no) 3개의 컬럼이 있는데 position은 직원의 직책이고 no는 사번이라고 생각하면 된다.
인덱스는 (position + no)에 걸어놓았다.
테스트를 위해서 데이터세팅을 해보았다. 아래와 같이 대충 insert가 되도록 하였다.
@Component
public class Runner implements CommandLineRunner {
private static final Logger log = LoggerFactory.getLogger(Runner.class);
@Autowired
JdbcTemplate jdbcTemplate;
@Override
public void run(String... args) {
List<Object[]> split = getDataSet().stream()
.map(data -> data.split(" "))
.collect(Collectors.toList());
split.forEach(data -> log.info(String.format("INSERT %s %s", data[0], data[1])));
jdbcTemplate.batchUpdate("INSERT INTO JAY_TECH(position, no) VALUES (?,?)", split);
}
private List<String> getDataSet() {
List<String> data = new ArrayList<>();
for (int i = [원하는 숫자]; i < [원하는숫자]; i++) {
data.add("a02 " + i);
}
return data;
}
}
@Configuration
@ComponentScan("com.jaytechblog.rdbtestdataset")
public class Config {
@Bean
public DataSource mysqlDataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3606/test");
dataSource.setUsername("root");
dataSource.setPassword("root");
return dataSource;
}
}
// build.gradle
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
runtimeOnly 'mysql:mysql-connector-java'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
docker 컨테이너 하나로 독립된 환경을 하나 만들고 jdbcTemplate를 사용하여 대충 밀어넣었다.
position이 a01인 사람을 대략 90만명 정도를 넣고, a02인 사람을 1천명, a03인 사람을 10만명 을 insert 하였다.
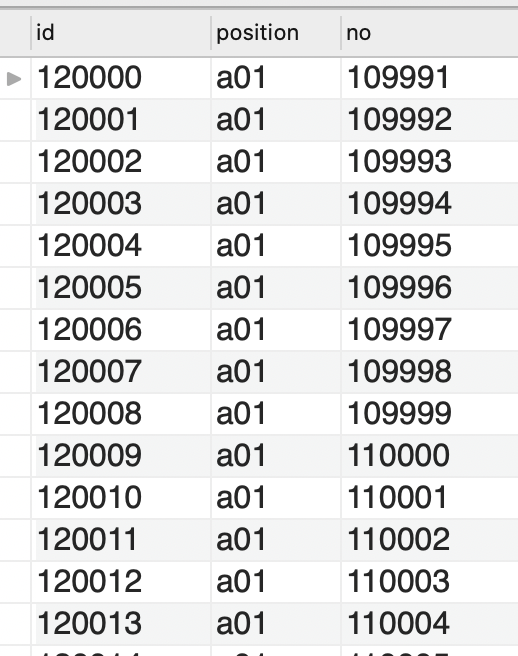
대략 위와 같이 들어가 있다.
BETWEEN
position이 a01, a02에서 사번이 109991인 사람을 찾는 쿼리는 아래와 같이 작성해볼 수 있다. (사번 숫자는 임의로 한 것임)
select * from test.JAY_TECH where position between 'a01' and 'a02' and no=109991;
위와 같이 한 명이 존재한다. 실행계획을 확인해보자.
BETWEEN의 실행계획
explain select * from test.JAY_TECH where position between 'a01' and 'a02' and no=109991;

실행계획을 보면 type에 range로 타는것을 볼 수 있다. 참고로 type은 MySQL 서버가 테이블의 레코드를 어떤 방식으로 읽었는지를 나타낸다. (type에 대한 자세한 내용은 추후 다루어보도록 하겠다)
어쨌든 index range scan이 이루어져 원하는대로 작동하는 것으로 보인다. 우측의 key에 my_idx선택하여 쿼리를 실행하였다. my_idx는 (position + no)로 인덱스를 걸어놓은 것이다.
하지만 rows 칼럼을 보면 대략 50만 rows를 다루는 것을 볼 수 있다. 내가 원하는건 하나의 row결과 인데 테이블의 절반가량을 읽는 것은 바람직하지 않아보인다.
between 조건으로 찾게된다면 테이블의 절반가량을 읽게되는 이유는 between이 선형으로 인덱스를 검색하기 때문이다. 포지션이 a01인 사람과 a02인 범위를 전부다 비교한다.
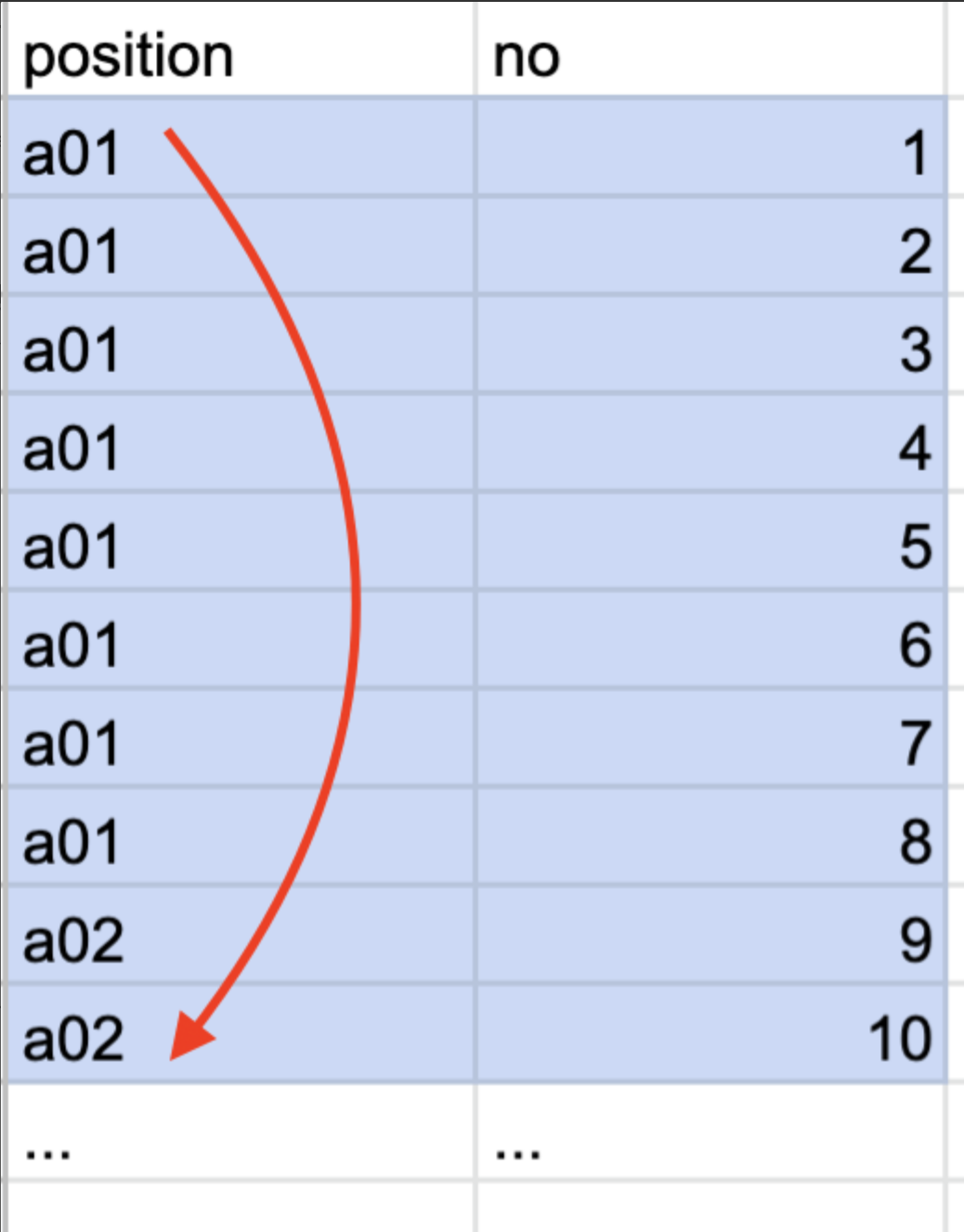
탐색의 효율을 높이려면 어떻게 해야할까?
IN
select * from test.JAY_TECH where position in ('a01', 'a02') and no=109991;
select * from test.JAY_TECH where position in ('a01', 'a02') and no=109991;in 으로도 같은 결과를 얻을 수 있다.
IN의 실행계획
실행계획을 확인해보자.

between을 사용했을 때 처럼 type은 range로 실행이 되었다. 하지만 rows를 보면 확연히 차이가 난다. 왜냐하면 IN을 사용한 쿼리는 (a01, 109991), (a02, 109991) 이렇게만 찾아보면 되기 때문이다.
IN을 사용하면 여러 값에 대해 동등 비교 연산을 수행한다. 여러 값이 비교가 될 테지만 범위로 검색하는 것이 아니라 여러 번의 동등비교로 실행되기 때문에 일반적으로 빠르게 처리된다.
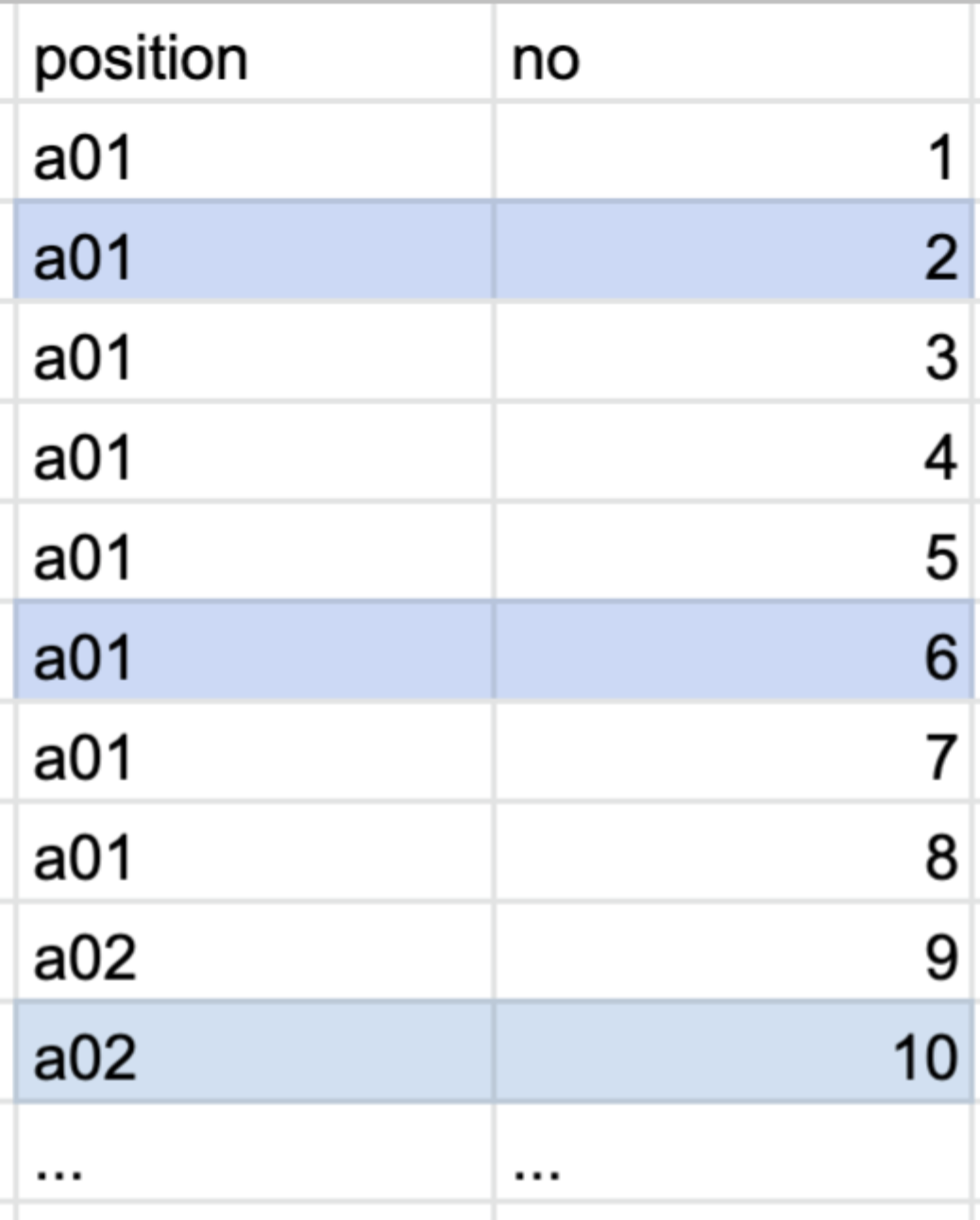
하지만 무조건 IN을 쓴다고 좋아지진 않는다. IN 에 들어가는 값들이 상수값이 아니라 서브 쿼리인 경우엔 느려질 수 있다. 상수값이 들어가는 경우는 기대한 인덱스가 타겠지만 서브 쿼리를 넣게 되면 그 서브쿼리가 먼저 실행되고나서 IN절로 들어가기 때문에 기대했던 결과를 얻기는 힘들 수 있다.
결론
인덱스 앞쪽에 있는 컬럼의 선택도가 떨어질 때는 IN으로 변경하여 쿼리의 성능을 개선해볼 수 있다.
'프로그래밍 > Database' 카테고리의 다른 글
| MySQL eq_range_index_dive_limit 를 활용한 쿼리 수행시간 개선 및 실무에서 발생할 수 있는 연관된 문제 (0) | 2021.05.16 |
|---|---|
| MySQL 잠금과 Isolation level에 대해서 (2) | 2021.01.16 |
| [데이터베이스] 동시 실행 제어 (Concurrency Control)와 공유 lock, 배타적 lock에 대해서 (0) | 2018.12.17 |
| [데이터베이스] 트랜잭션(Transaction)에대한 고찰 (2) | 2018.12.16 |
| [데이터베이스] 쿼리 최적화에 대해서 (Query Optimization) (2) | 2018.12.16 |