Enum 조회 성능 높여보기 - HashMap을 이용해서 빠르게 조회해보자
Enum 조회 성능 높여보기
자바의 Enum 에서 매핑을 할 때 find 메서드를 정의해서 알맞는 enum 을 찾는 로직을 많이 구현해본적이 있을 것 같아요.
다음과 같은 코드가 익숙하실텐테요. 저도 이런식으로 하다가 어느 날 친구가 인사이트를 주어 개선할 부분이 있는 것 같아 실험을 해보았습니다.
먼저 간단한 AccountStatus enum을 보겠습니다.
package com.jaytech.codepractice;
import java.util.stream.Stream;
import lombok.Getter;
@Getter
public enum AccountStatus {
INUSE("사용중"),
UNUSED("미사용"),
DELETED("삭제"),
UNKNOWN("알수없음");
private final String description;
AccountStatus(String description) {
this.description = description;
}
public static AccountStatus find(String description) {
return Arrays.stream(values())
.filter(accountStatus -> accountStatus.description.equals(description))
.findAny()
.orElse(UNKNOWN);
}
}아주 단순한 AccountStatus라는 enum을 정의했습니다. 지금 보면 find()로 들어오는 string으로 enum의 값을 찾습니다. 그리고 values()로 enum의 값에 대해 stream을 만들고 filter로 들어온 문자열과 맞는것을 찾습니다. 찾는게 없다면 UNKNOWN을 반환합니다.
뭐, 의도한대로 정상 작동합니다.
AccountStatus.find("사용중");
AccountStatus.find("unexpected value");이런식으로 하게 된다면 위에것은 INUSE에 해당하는 값이 나오고 밑에 것은 UNKNOWN이 나오게 되겠죠.
이제 몇 가지 방법을 통해 가장 빠른 것이 무엇인지 비교 해보겠습니다.
속도 측정해보기
위의 두 가지와 한 가지 훨씬 빠른방법이 있어서 소개합니다.
Arrays.stream 이용
public static AccountStatus find(String description) {
return Arrays.stream(values())
.filter(accountStatus -> accountStatus.description.equals(description))
.findAny()
.orElse(UNKNOWN);
}Streams.of 이용
public static AccountStatus find(String description) {
return Stream.of(values())
.filter(accountStatus -> accountStatus.description.equals(description))
.findAny()
.orElse(UNKNOWN);
}HashMap 이용
@Getter
public enum AccountStatus {
INUSE("사용중"),
UNUSED("미사용"),
DELETED("삭제"),
UNKNOWN("알수없음");
private final String description;
AccountStatus(String description) {
this.description = description;
}
private static final Map<String, AccountStatus2> descriptions =
Collections.unmodifiableMap(Stream.of(values())
.collect(Collectors.toMap(AccountStatus::getDescription, Function.identity())));
public static AccountStatus find(String description) {
return Optional.ofNullable(descriptions.get(description)).orElse(UNKNOWN);
}
}셋 중 가장 빠를것으로 예상되는 HashMap 이용방법입니다. 위의 두 개는 Arrays.stream 이든 Streams.of 이든 매번 스트림을 엽니다. 하지만 이 방법으로 쓴다면 Stream을 단 한번만 열면 됩니다.
private static final Map<String, AccountStatus2> descriptions =
Collections.unmodifiableMap(Stream.of(values())
.collect(Collectors.toMap(AccountStatus2::getDescription, Function.identity())));map을 만드는 부분입니다. 수정 불가한 map을 선언을 하고 values()를 돌려서 맵에 저장해 놓습니다. key는 enum 필드 값인 string이 들어가고 값은 Function.identity() 가 들어갑니다. 이것은 values()로 연 값들이(enum 값이 겠죠?) 하나씩 스트림 작업이 들어가게 되는데, 그냥 그대로 넣는다 라는 의미로 이해하시면 됩니다. 그렇게 되면 key에 string 값이 들어가게 되고 value에 enum이 들어갑니다.
결과적으로 find를 호출했을 때 map에서 키로 바로 찔러서 value 를 가져옵니다. 없다면 null이기 때문에 Optional로 명시적으로 처리해본다면 이렇게 할 수 있겠죠.
return Optional.ofNullable(descriptions.get(description)).orElse(UNKNOWN);대망의 속도 측정
@Test
void enum_속도_측정_stream_of_이용() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (int i = 0; i < 100000000; i++) {
AccountStatus.find("사용중");
}
for (int i = 0; i < 100000000; i++) {
AccountStatus.find("unexpected value");
}
stopWatch.stop();
System.out.println("Elapsed Time (Stream.of 이용) : " + stopWatch.getTotalTimeSeconds() + "s");
}
@Test
void enum_속도_측정_map_이용() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (int i = 0; i < 100000000; i++) {
AccountStatus2.find("사용중");
}
for (int i = 0; i < 100000000; i++) {
AccountStatus2.find("unexpected value");
}
stopWatch.stop();
System.out.println("Elapsed Time (HashMap 이용) : " + stopWatch.getTotalTimeSeconds() + "s");
}
@Test
void enum_속도_측정_arrays_stream_이용() {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (int i = 0; i < 100000000; i++) {
AccountStatus3.find("사용중");
}
for (int i = 0; i < 100000000; i++) {
AccountStatus3.find("unexpected value");
}
stopWatch.stop();
System.out.println("Elapsed Time (Arrays.stream 이용) : " + stopWatch.getTotalTimeSeconds() + "s");
}
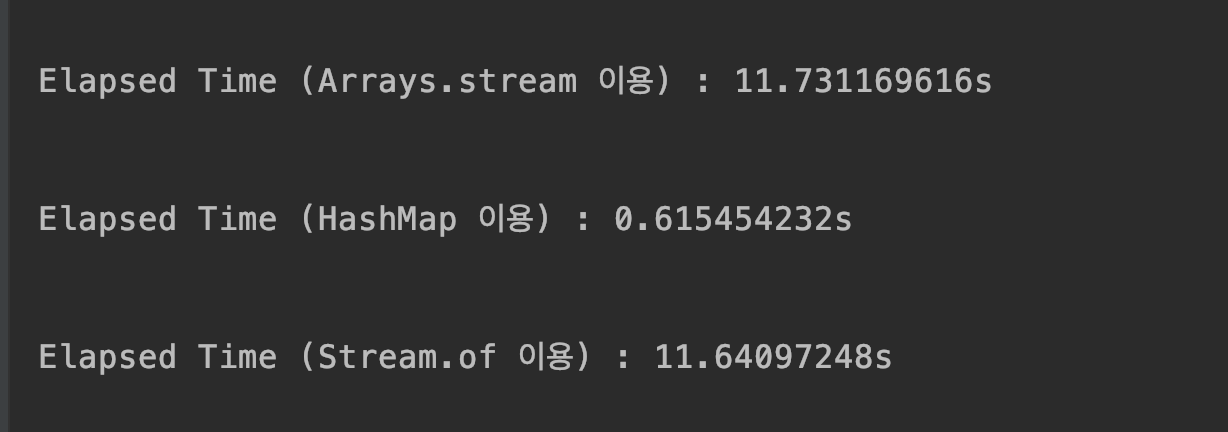
2억건의 처리를 해보았습니다. 속도를 봤을 때 확실히 HashMap을 이용한 방법이 빠르군요. 20배 정도 차이나는 것 같습니다. 물론 제 컴퓨터상 차이여서 환경에 따라 다를 수 있습니다.
그냥 참고) Arrays.stream과 Stream.of 의 차이
Arrays.stream과 Stream.of는 연속된 스트림을 찾는데 보편적으로 이용됩니다. non-primitive 타입에 대해서는 둘 다 Stream를 반환합니다.
Integer[] array = { 1, 2, 3, 4, 5 };
Stream.of(array)
.forEach(System.out::println);
Integer[] array = { 1, 2, 3, 4, 5 };
Stream.of(array)
.forEach(System.out::println); 즉 위와 아래는 같은 반환형을 갖습니다. 차이는 어디서 생길까요?
바로 primitive type에서 생깁니다. 원시형을 넣는데 있어 Arrays.stream()은 IntStream을 반환하고 Stream.of는 Stream<int[]>를 반환합니다. 그래서 같은 코드를 실행했을 때 값이 다르게 나옵니다.
int[] array = { 1, 2, 3, 4, 5 };
Arrays.stream(array) // returns IntStream
.forEach(System.out::println);
int[] array2 = { 1, 2, 3, 4, 5 };
Stream.of(array2) // returns Stream<int[]>
.forEach(System.out::println); // prints [I@27d6c5e0그렇기 때문에 Stream.of를 사용시 flatMapToInt로 IntStream으로 변환시킨 후 출력해야 정상 출력이 됩니다.
Arrays.stream은 int, long, double 의 원시형 타입에 (primitive type)에 대해서 오버로딩이 되어 있습니다. 다른 원시형 타입에 대해서는 Arrays.stream()이 동작하지 않습니다.
이런 차이가 있는데 속도 측정 시 이해가 되지않는 부분은... Streams.of를 사용할 때 메서드를 들어가보면 Arrays.stream을 사용하는데 왜 속도가 더 빠르게 측정이 되는지 모르겠습니다. 알게모르게 최적화를 하는걸까요. 이 부분에 대해서 알게되면 게시글 수정을 해놓겠습니다.